이번 글에서는 최소 신장 트리 (MST, Minimum Spanning Tree)에 대해 알아보겠습니다.
목차
최소 신장 트리란?
유니온-파인드 자료구조
크루스칼 알고리즘
정리
최소 신장 트리란?
최소 신장 트리(MST, Minimum Spanning Tree)에 대해서 알아보자.
트리(Tree)란?
트리(Tree)란 노드 N개와 N-1개의 간선으로 이루어져 있으며 모든 노드가 서로 연결되어 있는 구조이다.
즉, 트리는 그래프에 포함되는 개념이며 그래프의 특별한 경우라고 할 수 있다
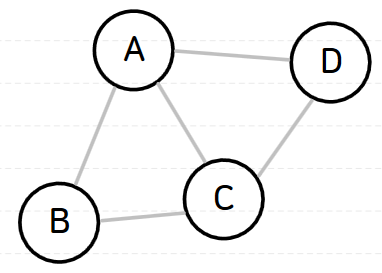
예를 들어, 아래의 그래프는 간선의 개수가 '노드의 개수-1'이므로 트리라고 할 수 있으며
아래의 그래프는 간선의 개수는 '노드의 개수-1'이지만 노드 D가 다른 노드들과 연결되어 있지 않으므로 트리라고 할 수 없다.
트리의 특징으로는 간선의 개수는 항상 '노드의 개수-1'이며 모든 노드가 연결되어 있다는 점이 있다.
또한, 트리는 사이클이 없다는 특징도 있다.
모든 노드가 연결되어 있으며 간선의 개수가 '노드의 개수-1'인 경우에는 사이클 자체가 생길 수 없다
신장 트리(Spanning Tree)란?
신장 트리(Spanning Tree)는 양방향 그래프에서 모든 노드를 포함하고 간선의 일부를 포함하여 만들어진 트리를 의미한다.
예를 들어, 다음과 같은 양방향 그래프가 있다고 해보자.
한 그래프에 대한 신장 트리는 여러 개가 나올 수 있으며, 위 그래프의 신장 트리 중 몇 개를 살펴보면 다음과 같다.
최소 신장 트리(MST, Minum Spanning Tree)란?
최소 신장 트리(MST)는 양방향 가중 그래프에서 정의되며, 신장 트리 중에서 가중치의 합이 최소가 되는 신장 트리를 의미한다.
예를 들어, 다음과 같은 양방향 가중 그래프가 있다고 해보자.
이때, 여러 개의 신장트리가 나올 수 있으며 신장 트리 중 가중치의 합이 가장 작은 것은 8이다.
따라서, 위 그래프에 대한 최소 신장 트리는 다음과 같다.
최소 신장 트리 (가중치 합: 8)
이번 글의 목표는 양방향 가중 그래프가 주어졌을 때 최소 신장 트리(MST)를 구하는 것이며
이때 필요한 개념으로 유니온-파인드(Union-Find) 자료구조와 크루스칼(Kruskal) 알고리즘 등이 있다.
유니온-파인드 자료구조
유니온-파인드(Union-FInd) 자료구조는 서로소 집합(disjoint set)을 표현한 자료구조이다.
서로소 집합(disjoint set)이란 한 원소가 둘 이상의 집합에 포함되지 않는 집합을 의미한다.
예를 들어, 다음과 같은 원소가 있다고 하면
아래와 같은 집합은 각 원소가 한 집합에만 들어가 있기 때문에 서로소 집합이지만
아래와 같은 집합은 원소 2가 두 집합에 포함되어 있으므로 서로소 집합이 아니다.
이러한 서로소 집합(disjoint set)을 코드로 구현한 자료구조가 유니온-파인드(Union-Find) 자료구조이다.
유니온-파인드 자료구조는 다음과 같은 3가지 연산을 지원한다.
find(x): 원소 x가 속한 집합의 대표 원소를 반환한다.
same(a, b): 원소 a와 원소 b가 같은 집합인지를 판단하여 true, false 형태로 반환한다.
unite(a, b): 원소 a와 원소 b가 속한 집합을 합친다.
유니온-파인드 자료구조를 구현하는 법은 1차원 배열을 사용하여 각 원소가 해당 집합의 대표 원소를 저장하게 하면 된다.
정확히는, 각 원소에 저장된 원소를 따라가다 보면 해당 집합의 대표 원소를 찾을 수 있는 것이다
(경로를 따라가다 자기 자신을 가리키는 원소가 나오면 그 원소가 대표 원소인 것이다)
예를 들어, 다음과 같은 서로소 집합을 1차원 배열로 표현한다고 하면 (각 집합의 대표 원소는 파란색 원소이다.)
아래와 같이 표현할 수 있다.
이제, 유니온-파인드 자료구조에서 지원하는 3가지 연산을 구현해 보자.
(유니온-파인드 자료구조에서 대표 원소로 가는 경로를 저장하는 1차원 배열을 link라고 하겠다.)
find(x)
원소 x가 속한 집합의 대표 원소를 반환해야 하므로 link배열을 이용하여 대표 원소를 구하면 된다.
int find(int x) {
if (link[x] == x) return x;
else return find(link[x]);
}
same(a, b)
원소 a가 속한 집합의 대표 원소와 원소 b가 속한 집합의 대표 원소가 같은지를 확인하면 된다.
bool same(int a, int b) {
return find(a) == find(b);
}
unite(a, b)
원소 b가 속한 집합의 대표 원소를 원소 a가 속한 집합의 대표 원소를 가리키게(저장하게) 하면 된다. (원소 a가 속한 집합의 대표 원소를 원소 b가 속한 집합의 대표 원소를 가리키게(저장하게) 해도 된다.)
void unite(int a, int b) {
a = find(a);
b = find(b);
if (a == b) return; // 이미 같은 집합이면 종료
link[b] = a;
}
유니온-파인드 연산 최적화
서로소 집합을 1차원 배열로 표현할 때 어떻게 표현하냐에 따라서 그 효율성이 달라진다.
예를 들어, 다음과 같은 서로소 집합이 있다고 해보자.
이때, 이를 1차원 배열로 표현하면 여러 가지 경우가 나올 수 있으며 2가지 경우만 살펴보도록 하자.
case1case2
원소 1의 대표 원소를 찾는 과정을 살펴보자.
'case1'의 경우, link배열을 이용하여 구하면1→2→3→4→5을 통해 4번에 거쳐서 대표 원소가 5임을 알 수 있다.
반면, 'case2'의 경우, link배열을 이용하여 구하면1→5을 통해 1번 만에 대표 원소가 5임을 알 수 있다.
즉, 서로소 집합을 1차원 배열로 표현할 때 대표 원소까지 가는 과정을 최소화해야 더 효율적이다!
유니온-파인드 자료구조에서find함수와unite함수를 조금 수정함으로써 최적화할 수 있다.
find(x)
원소 x가 속한 집합의 대표 원소를 찾아갈 때, 그 과정에서 거친 모든 원소가 대표 원소를 가리키게(저장하게) 한다.
int find(int x) {
if (link[x] == x) return x;
else return link[x] = find(link[x]);
}
unite(a, b)
원소 a가 있는 집합과 원소 b가 있는 집합을 합칠 때, 크기가 작은 집합을 크기가 큰 집합에 합친다. 이를 구현하려면, 집합의 크기를 저장하는 배열 sz을 만들어줘야 한다. sz배열의 초기 상태는 보통 아래와 같은 형태이며, 집합이 합쳐지는 과정을 거치면서 sz배열은 갱신된다.
void unite(int a, int b) {
a = find(a);
b = find(b);
if (a == b) return;
if (sz[a] < sz[b]) swap(a, b);
sz[a] += sz[b]; sz[b] = 0;
link[b] = a;
}
시간 복잡도
원소의 개수를 N개라 하면,
최적화를 하지 않았을 경우에 find함수의 시간 복잡도는 최대 $O(N)$이며, union함수의 시간 복잡도는 $O(1)$이다.
최적화를 했을 경우에 find함수의 시간 복잡도는 최대 $O(α)$이며, union함수의 시간 복잡도는 $O(1)$이다.
(여기서 $α$는 매우 작은 자연수이며 따라서 $O(1)$라고 생각해도 무방하다.)
크루스칼 알고리즘
크루스칼(Kruskal) 알고리즘은 양방향 가중 그래프의 최소 신장 트리(MST)를 찾는 알고리즘이다.
크루스칼 알고리즘은 그리디 기반으로 가중치가 낮은 간선을 추가해 가면서 최소 신장 트리(MST)를 찾는다.
트리에서 노드의 개수가 N개 일 때, 간선의 개수는 N-1개이다.
따라서, 크루스칼 알고리즘에서 간선을 추가하는 과정을 N-1번 하면 최소 신장 트리(MST)를 찾은 것이다.
주의할 점은 간선을 추가할 때 사이클이 생기지 않도록 간선을 추가해야 한다는 점인데,
이는 간선으로 연결되어 있는 노드들을 같은 집합으로 취급하면 쉽게 해결할 수 있다.
가중치가 낮은 간선을 먼저 살펴보는 것은 간선 리스트를 가중치가 낮은 순서대로 정렬을 하면 되고,
(사이클이 생기지 않도록) 추가하려는 간선의 양끝 노드가 이미 같은 집합인지 판단하는 것은 유니온-파인드 자료구조를 쓰면 된다.
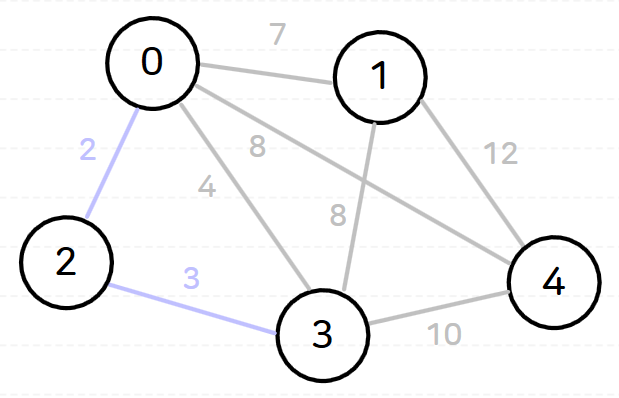
다음과 같은 양방향 가중 그래프에 대해 크루스칼 알고리즘을 수행해 보자.
노드 0을 기준으로 유니온-파인드 자료구조를 이용 수행하면 다음과 같은 과정이 순서대로 일어난다.
초기 상태가중치가 2인 간선 추가가중치가 3인 간선 추가가중치가 4인 간선 추가x (노드 0과 노드 3은 이미 같은 집합에 있음)가중치가 7인 간선 추가가중치가 8인 간선 추가x (노드 1과 노드3은 이미 같은 집합에 있음)가중치가 8인 간선 추가노드의 개수는 5개이며, 간선을 4개 추가했으므로 종료
위와 같이 크루스칼 알고리즘을 진행하면 최소 신장 트리(MST)를 구할 수 있다.
(위 그림에서 모든 노드와 파란색 간선으로 이루어진 트리가 최소 신장 트리이다.)
이때, 최소 신장 트리 가중치의 합은 추가한 간선의 가중치의 합으로 구할 수 있으며 위 예시에서는 20이다.
이를 구현하는 법은 간선 리스트를 정렬하여 가중치가 낮은 간선부터 살펴보며 간선을 추가하면 된다.
이때, 사이클이 생기는 경우(두 노드가 이미 같은 집합인 경우)에는 건너뛰면서 진행하면 된다.
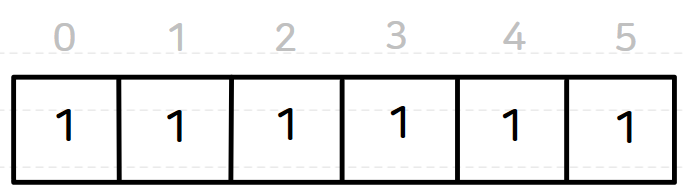
참고로, 이때 사용하는 유니온-파인드 자료구조의link배열과sz배열의 초기 상태는 다음과 같다.
link 배열sz 배열
크루스칼 알고리즘을 간선 리스트와 유니온-파인드 자료구조를 이용하여 코드로 구현하면 다음과 같다.
크루스칼 알고리즘은 간선 리스트를 정렬할 때 $O(M \cdot log M)$, N-1개의 간선을 추가할 때 $O(N \cdot α)$의 시간이 걸린다.
따라서, 크루스칼 알고리즘의 시간 복잡도는 $O(M \cdot log M)$이다. ($N$: 노드의 개수, $M$: 간선의 개수, $α$: 매우 작은 자연수)
정리
이번 시간에 최소 신장 트리와 최소 신장 트리를 구하는 알고리즘인 크루스칼 알고리즘에 대해서 알아보았다.
추가로, 크루스칼 알고리즘을 구현할 때 필요한 자료구조인 유니온-파인드 자료구조에 대해서도 알아보았다.
유니온-파인드 자료구조
유니온-파인드 자료구조는 서로소 집합(distjoint set)을 표현할 때 사용하는 자료구조이다.
크루스칼 알고리즘을 구현할 때도 쓰이지만 유니온-파인드 자료구조는 그 자체로도 많이 쓰인다

![[18강] 최소 신장 트리 (MST)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FdDxlP8%2FbtrVDhZQaxf%2Fjo1j3RUtvY7jtyU5Mi6od1%2Fimg.png)